Search Jobs Experimental
Use Search Jobs to search code at scale for large-scale organizations.
Search Jobs allows you to run search queries across your organization's codebase (all repositories, branches, and revisions) at scale. It enhances the existing Sourcegraph's search capabilities, enabling you to run searches without query timeouts or incomplete results.
With Search Jobs, you can start a search, let it run in the background, and then download the CSV file results from the Search Jobs UI when it's done. Site administrators can enable or disable the Search Jobs feature, making it accessible to all users on the Sourcegaph instance.
Enable Search Jobs
To enable Search Jobs, you need to configure a managed object storage service to store the results of your search jobs and then enable the feature in the site administration.
Storing search results
By default, search jobs stores results using the blobstore service. To target a managed object storage service, you must set a handful of environment variables for configuration and authentication to the target service.
- If you are running a
sourcegraph/serverdeployment, set the environment variables on the server container - If you are running via Docker-compose or Kubernetes, set the environment variables on the
frontendandworkercontainers
Using S3
Set the following environment variables to target an S3 bucket you've already provisioned. Authentication can be done through an access and secret key pair (and optionally through session token) or via the EC2 metadata API.
SEARCH_JOBS_UPLOAD_BACKEND=S3SEARCH_JOBS_UPLOAD_BUCKET=<my bucket name>SEARCH_JOBS_UPLOAD_AWS_ENDPOINT=https://s3.us-east-1.amazonaws.comSEARCH_JOBS_UPLOAD_AWS_ACCESS_KEY_ID=<your access key>SEARCH_JOBS_UPLOAD_AWS_SECRET_ACCESS_KEY=<your secret key>SEARCH_JOBS_UPLOAD_AWS_SESSION_TOKEN=<your session token>(optional)SEARCH_JOBS_UPLOAD_AWS_USE_EC2_ROLE_CREDENTIALS=true(optional; set to use EC2 metadata API over static credentials)SEARCH_JOBS_UPLOAD_AWS_REGION=us-east-1(default)
Using GCS
Set the following environment variables to target a GCS bucket you've already provisioned. Authentication is done through a service account key, either as a path to a volume-mounted file or the contents read in as an environment variable payload.
SEARCH_JOBS_UPLOAD_BACKEND=GCSSEARCH_JOBS_UPLOAD_BUCKET=<my bucket name>SEARCH_JOBS_UPLOAD_GCP_PROJECT_ID=<my project id>SEARCH_JOBS_UPLOAD_GOOGLE_APPLICATION_CREDENTIALS_FILE=</path/to/file>SEARCH_JOBS_UPLOAD_GOOGLE_APPLICATION_CREDENTIALS_FILE_CONTENT=<{"my": "content"}>
Provisioning buckets
If you would like to allow your Sourcegraph instance to control the creation and lifecycle configuration management of the target buckets, set the following environment variables:
SEARCH_JOBS_UPLOAD_MANAGE_BUCKET=true
Site adminstration
- Login to your Sourcegraph instance and go to the site admin
- Next, click the site configuration
- From here, you'll see
experimentalFeatures - Set
searchJobstotrueand then refresh the page
Using Search Jobs
To use Search Jobs, you need to:
- Run a search query from your Sourcegraph instance
- Click the result menu below the search bar to see if your query is valid for the long search
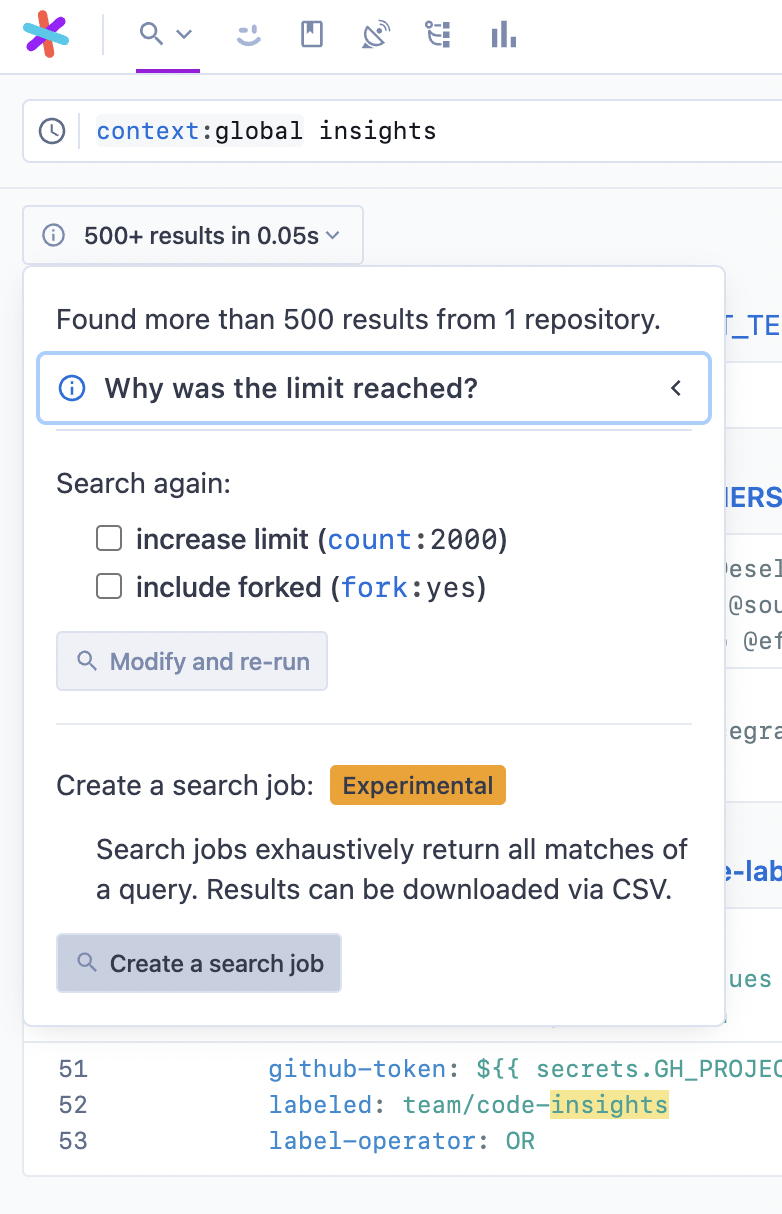
- If your query is valid, click Run search job to initiate the search job
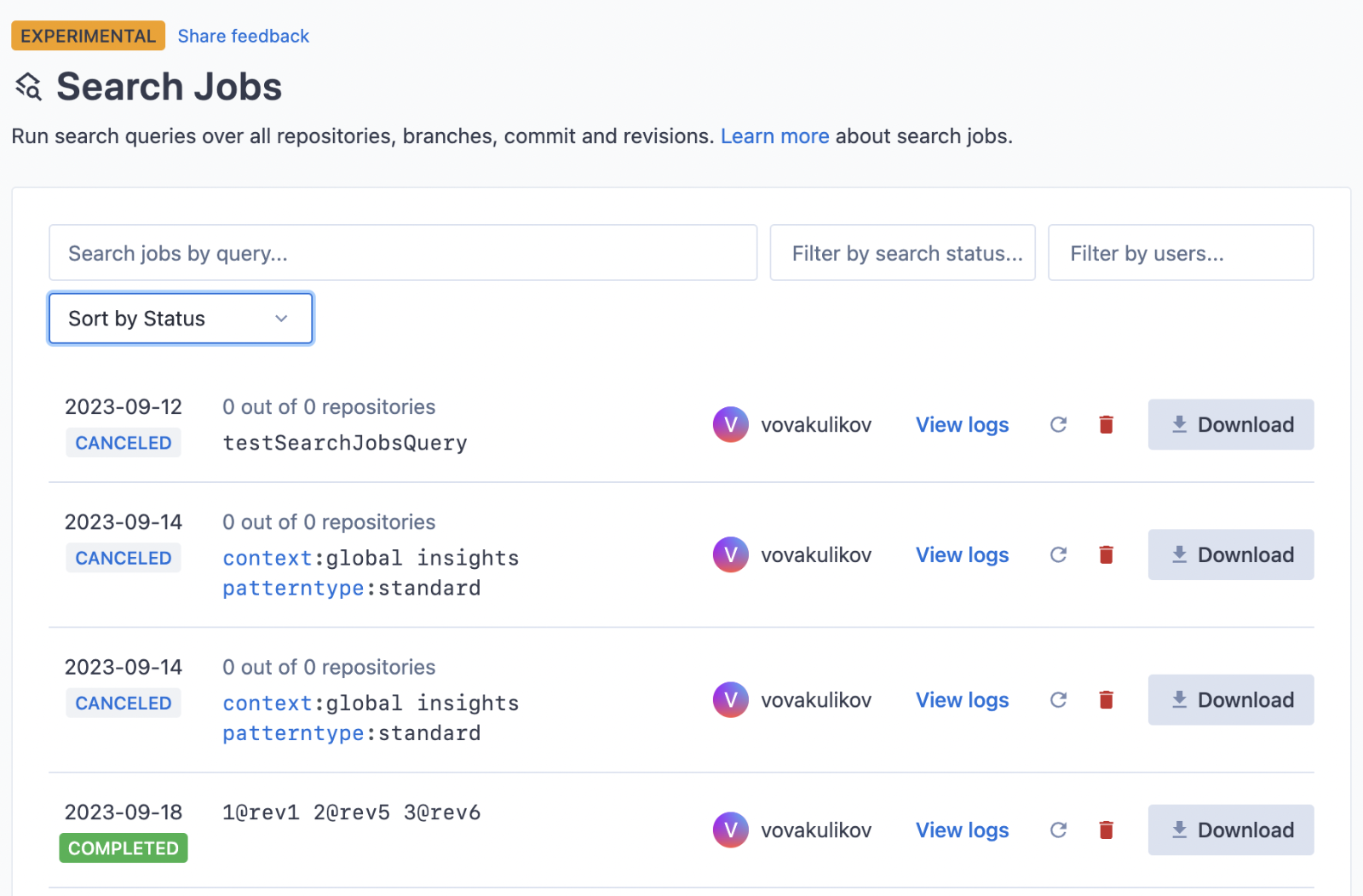
- You will be redirected to the "Search Jobs UI" page at
/search-jobs, where you can view all your created search jobs. If you're a site admin, you can also view search jobs from other users on the instance
Limitations
Search Jobs supports queries of type:file and it automatically appends this to the search query. Other result types (like diff, commit, path, and repo) will be ignored. However, there are some limitations on the supported query syntax. These include:
OR,ANDoperators- file predicates, such as
file:has.content,file:has.owner,file:has.contributor,file:contains.content .*regexp search- Multiple
revfilters - Queries with
index: filter