Developing an out-of-band migration
Normal migrations apply a sequence of pure-SQL migrations (each in a transaction) to the database on application startup. This happens to block the new application version from reaching a working state until all migrations since the previous version have been applied. This is generally a non-issue as most schema migrations are fast, and most data migrations are fast enough to apply on application startup.
Out-of-band migrations allow for application-specific logic to exist in a migration that can't be easily performed within a SQL command. For example:
- generating key pairs
- re-hashing passwords
- decoding and interpreting opaque payloads
- fetching data from another remote API or data store based on existing data
- transforming large scale data
Remember - the longer we block application startup on migrations, the more vulnerable an instance will become to downtime as no new frontend containers will be able to service requests. In these cases, you should define an out of band migration, which is run in the background of the application over time instead of at startup.
Some background tasks may seem initially well-suited for an out-of-band migration, but may actually be better installed as a permanent background job that runs periodically. Such jobs include data transformations that require external state to determine its progress. For example, database encryption jobs were originally written as out-of-band migrations. However, changing the external key in the site configuration can drop progress back to 0%, despite having already ran to completion.
Overview
An out-of-band migration is defined with the following data:
- an owning team (e.g.
codeintel) - an affected component (e.g.
codeintel-db.lsif_data_documents) - a human-readable description (e.g.
Populate num_diagnostics from gob-encoded payload) - the version when the migration was introduced (e.g.
3.25.0) - the version when the migration was deprecated (if any)
- a flag indicating whether or not the migration is non-destructive
- a flag indicating whether or not the migration is enterprise-only
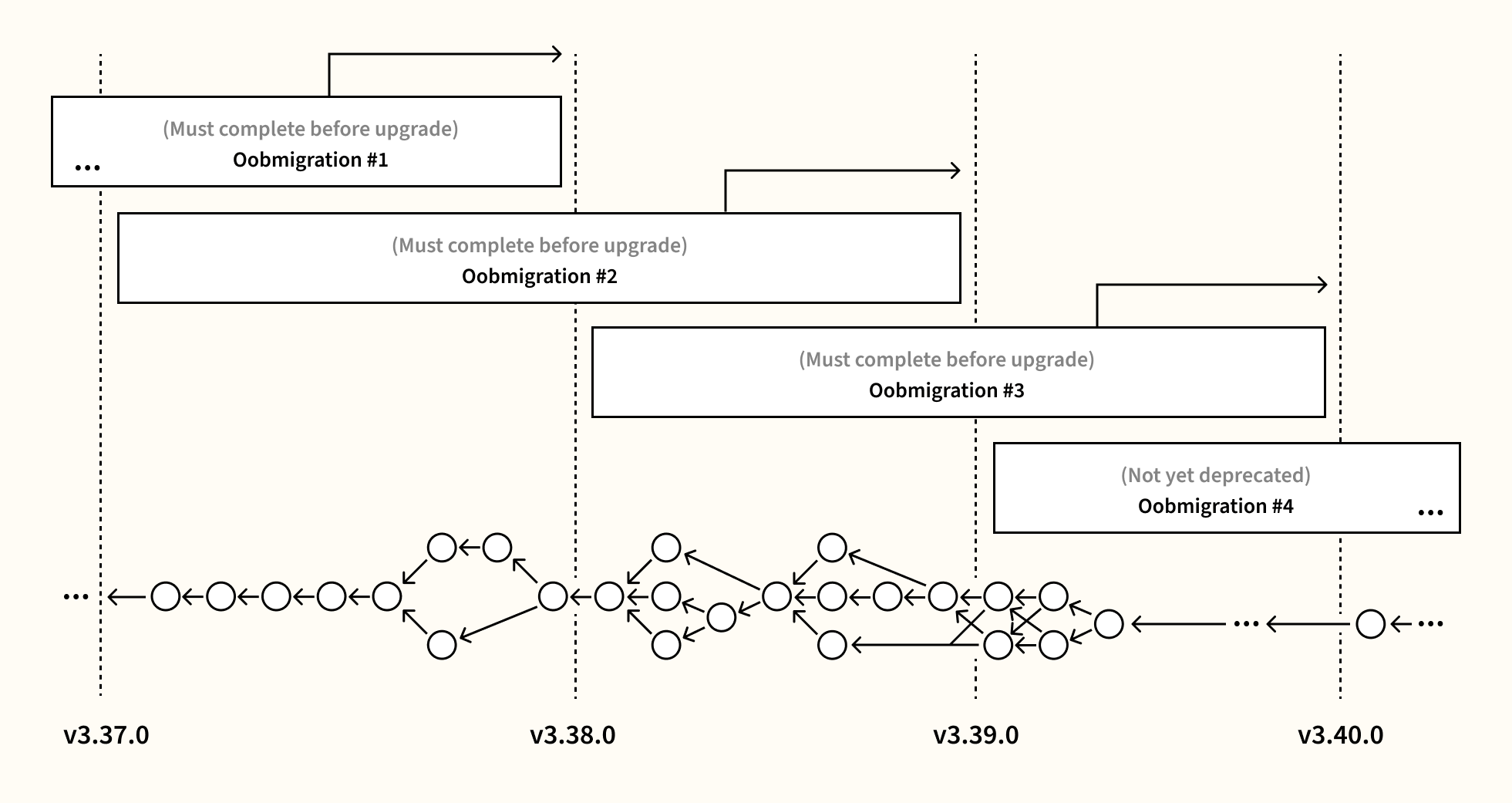
Each out-of-band migration is associated with a migrator instance, which periodically runs in the background of Sourcegraph instances between the version the migration was introduced (inclusive) and the version the migration was marked as deprecated (exclusive). Each migrator instance enables three behaviors:
- Perform a batch of the migration
- Perform a batch of the migration in reverse
- Determine the percentage of data that has been migrated
For every registered migrator, the migration runner will periodically check for the migration progress (even if it's finished). If the migrator has more work to do, then the runner will periodically have it perform a batch of the migration in the background. Errors that occur during migrations are logged to the migration record and are exposed to the site-admin.
Upgrades
Site-admins will be prevented from upgrading beyond the version where an incomplete migration has been deprecated. i.e., site-admin must wait for these migrations to finish before an upgrade. Otherwise, the instance will have data in a format that is no longer readable by the new version. In these cases, the instance will shut down with an error message similar to what happens when an in-band migration fails to apply.
The Site Admin > Maintenance > Migrations page shows the current progress of each out-of-band migration, as well as disclaimers warning when an immediate upgrade would fail due to an incomplete migration.
Downgrades
If a migration is non-destructive (it only adds data), then it is safe to downgrade to a previous version. If a migration is destructive (it removes or changes the shape of data), then the migration must be run in reverse. We can do this by flipping the direction of the migration record. The runner takes care of the rest.
It is not valid for a user to downgrade beyond the version in which a non-0% migration was introduced. Site-admin must wait for these migrations to completely revert before a downgrade. Otherwise, the instance will have data in a format that is not yet readable by the old version.
In order to run the 'down' side of a migration, set the apply_reverse field to the migration row in the out_of_band_migrations table via psql or the graphql API.
Backwards compatibility
Because this happens in the background over time, the application must able to read both the new and old data formats until the migration has been deprecated. Advice for this is highly dependent on the type of data migration, but there are a few general options:
Migrate to a new column: Migrate data from col to col_migrated (a new column). If data is moved destructively (it may be expensive to keep both versions), then the down migration must be able to produce a payload in the previous shape to support downgrades. Progress can be determined by finding the ratio between the number of records with a non-null col_migrated and the total number of records. Reads can query both fields, and decode whichever field is populated. The old column can be dropped after the migration has been deprecated.
Version each row: Introduce a schema_version column (with a default of 1) to the table undergoing migration. Then, bump the schema_version on up migrations and decrement it on down migrations (along with other migration actions). Progress can be determined by finding the ratio between the number of records with schema_version >= 2 and the total number of records. Reads can check the schema version of each row to decide how to interpret the raw data. Subsequent migrations on this table can use the same schema version column, but with higher numbers. This version column can be dropped after all migrations using that field have been deprecated.
Adding a new migration
This guide will show you how to add a new out-of-band migration. We are migrating the following table:
CREATE TABLE skunk_payloads ( id serial primary key, payload text NOT NULL );
Step 1: Add migration record
The first step is to declare metadata for a new migration. Add a new entry to the file internal/oobmigration/oobmigrations.yaml.
- id: 42 -- This must be consistent across all Sourcegraph instances team: skunkworks -- Team owning migration component: db.skunk_payloads -- Component being migrated description: Re-encode our skunky data -- Human-readable description non_destructive: true -- Can be read with previous version without down migration is_enterprise: true -- Should not run in OSS versions or the migration code is only available in enterprise introduced_major_version: 3 -- The current major release introduced_minor_version: 34 -- The current minor release
Step 2: Modify reads
Before we start writing records in a new format (either from migrated existing records or new writes), we need to ensure we can read the new and old formats. Consider queries with the given result shape.
SELECT payload, payload2 FROM skunk_payloads ...
We can create a scanner function to read this data as follows.
func scanSkunkPayloads(rows *sql.Rows, queryErr error) ([]string, error) { if queryErr != nil { return nil, queryErr } defer func() { err = basestore.CloseRows(rows, err) }() var payloads []string for rows.Next() { var oldPayload, newPayload string if err := rows.Scan(&dbutil.NullString{S: &oldPayload}, &dbutil.NullString{S: &newPayload}); err != nil { return nil, err } if newPayload != "" { // Decode in new way payloads = append(payloads, decodeNew(newPayload)) } else if oldPayload != nil { // Decode in old way payloads = append(payloads, decodeOld(oldPayload)) } } return payloads, nil }
Step 3: Modify writes
Now that we can read both formats, it is safe to start writing all new records using the new format.
Step 4: Register migrator
Next, we need to move all of the existing data in the old format into the new format. We'll first define a migrator instance.
import "github.com/sourcegraph/sourcegraph/internal/oobmigration" type migrator struct { store *basestore.Store } func NewMigrator(store *basestore.Store) oobmigration.Migrator { return &migrator{store: store} }
This migrator reports progress by counting the number of records with its new field populated over the total number of records (and special-cases empty tables as being completely converted as no records are in the old format).
func (m *migrator) Progress(ctx context.Context, _ bool) (float64, error) { progress, _, err := basestore.ScanFirstFloat(m.store.Query(ctx, sqlf.Sprintf(` SELECT CASE c2.count WHEN 0 THEN 1 ELSE cast(c1.count as float) / cast(c2.count as float) END FROM (SELECT count(*) as count FROM skunk_payloads WHERE payload2 IS NOT NULL) c1, (SELECT count(*) as count FROM skunk_payloads) c2 `))) return progress, err }
In the case of enterprise migrations you will want your Progress function to report success if your enterprise feature is disabled.
In the forward migration direction, we want to select a record that is in the previous format (we can tell here by the absence of a payload2 field), and update that record with the result of some external computation. Here, we're going to rely on an oracle function oldToNew that converts the old format into the new format.
const BatchSize = 500 func (m *migrator) Up(ctx context.Context) (err error) { tx, err := m.store.Transact(ctx) if err != nil { return err } defer func() { err = tx.Done(err) }() // Select and lock a single record within this transaction. This ensures // that many worker instances can run the same migration concurrently // without them all trying to convert the same record. rows, err := tx.Query(ctx, sqlf.Sprintf( "SELECT id, payload FROM skunk_payloads WHERE payload2 IS NULL ORDER BY id LIMIT %s FOR UPDATE SKIP LOCKED", BatchSize, )) if err != nil { return err } defer func() { err = basestore.CloseRows(rows, err) }() // We don't have access to a connection pool and hence cannot write and read // from a result set in parallel within in transaction. Therefore, we need to // collect all results before executing update commands. updates := make(map[int]string) // id -> payload for rows.Next() { var id int var payload string if err := rows.Scan(&id, &payload); err != nil{ return err } updates[id] = oldToNew(payload) } for id, payload := range updates { if err := tx.Exec(ctx, sqlf.Sprintf( "UPDATE skunk_payloads SET payload2 = %s WHERE id = %s", payload, id, )); err != nil { return err } } return nil }
In the reverse migration direction, we may think we can take a few short-cuts because we don't actually destroy any data in the payload field. However, it would be a mistake to simply remove the payload2 data as we're only writing to payload2 and not to the original payload column for new data. This would also be a problem if our up migration set payload = NULL on update to save space. Again, we rely on an oracle function newToOld that converts the new format into the old format.
func (m *migrator) Down(ctx context.Context) (err error) { // Drop migrated records that still have the old payload if err := m.store.Exec(ctx, sqlf.Sprintf( "UPDATE skunk_payloads SET payload2 = NULL WHERE payload IS NOT NULL AND payload2 IS NOT NULL LIMIT %s", BatchSize, )); err != nil { return err } // For records that were written in the new format, we need to calculate // the old format from the new format. This should be exactly the inverse // of the forward migration. tx, err := m.store.Transact(ctx) if err != nil { return err } defer func() { err = tx.Done(err) }() rows, err := tx.Query(ctx, sqlf.Sprintf( "SELECT id, payload2 FROM skunk_payloads WHERE payload IS NULL LIMIT %s FOR UPDATE SKIP LOCKED", BatchSize, )) if err != nil { return err } defer func() { err = basestore.CloseRows(rows, err) }() // We don't have access to a connection pool and hence cannot write and read // from a result set in parallel within in transaction. Therefore, we need to // collect all results before executing update commands. updates := make(map[int]string) // id -> payload for rows.Next() { var id int var payload string if err := rows.Scan(&id, &payload); err != nil{ return err } updates[id] = newToOld(payload) } for id, payload := range updates { if err := tx.Exec(ctx, sqlf.Sprintf( "UPDATE skunk_payloads SET payload = %s WHERE id = %s", payload, id, )); err != nil { return err } } return nil }
Lastly, in order for this migration to run, we need to register it to the out of band migrator runner instance in the OSS or enterprise worker service.
// `db` is the database.DB migrator := NewMigrator(basestore.NewWithHandle(db.Handle())) if err := outOfBandMigrationRunner.Register(42, migrator, oobmigration.MigratorOptions{Interval: 3 * time.Second}); err != nil { return err }
Here, we're telling the migration runner to invoke the Up or Down method periodically (once every three seconds) while the migration is active. The migrator batch size together with this interval is what controls the migration throughput.
Step 5: Mark deprecated
Once the engineering team has decided on which versions require the new format, old migrations can be marked with a concrete deprecation version. The deprecation version denotes the first Sourcegraph version that no longer runs the migration, and is no longer guaranteed to successfully read un-migrated records.
New fields can be added to the existing migration metadata entry in the file internal/oobmigration/oobmigrations.yaml.
- id: 42 team: skunkworks component: db.skunk_payloads description: Re-encode our skunky data non_destructive: true is_enterprise: true introduced_version_major: 3 introduced_version_minor: 34 # NEW FIELDS: deprecated_version_major: 3 -- The upcoming major release deprecated_version_minor: 39 -- The upcoming minor release
This date may be known at the time the migration is created, in which case it is fine to set both the introduced and the deprecated fields at the same time.
Note that it is not advised to set the deprecated version to the minor release of Sourcegraph directly following its introduction. This will not give site-admins enough warning on the previous version that updating with an unfinished migration may cause issues at startup or data loss.
Step 6: Deprecation
Despite an out of band migration being marked deprecated, it may still need to be executed by multi-version upgrades in a later version. For this reason it is not safe to delete any code from the out of band migrations until after the deprecation version falls out of the supported multi-version upgrade window.
As an alternative to deleting the code, the out of band migration can be isolated from any dependencies outside of the out of band migration. For example copying any types, functions, and other code that is used to execute the migration. Once isolated, the migration can be considered frozen and effectively ignored. To see an example, see the Code Insights settings migration
It is important to note that breaking changes to the database using an in-band migration are safe to execute after the marked deprecation version for the out of band migration, even if they would logically break the code of the out of band migration. This is because the multi-version upgrade will execute the out of band migration sequentially with in-band migrations. Once executed, the out of band migration will see the database in the state it was at when prior to being marked deprecated.
{kind=link}
To clarify, here is a concrete example of a valid series of events to deprecate an out of band migration:
3.41 - table A is introduced 3.42 - table B is introduced 3.43 - an out of band migration is created to migrate from A -> B 3.45 - the out of band migration is marked deprecated and isolated in the codebase 3.46 - table A is removed 3.48 - a user successfully performs a multi-verion upgrade from 3.40 -> 3.48, including the out of band migration