Writing an indexer
This page is a deep-dive into LSIF (Language Server Index Format) and is meant to be a general guide to writing an LSIF indexer for a language that isn't already supported on LSIF.dev. If you are interested in adding your LSIF indexer to the list, create a pull request here. Sourcegraph currently reads versions 0.4.0 and 0.4.3 of the LSIF specification, but will continue to add the ability to read newer versions of the specification as they are published. Reference Microsoft's documentation as an additional resource.
LSIF
The LSIF output format accepted by Sourcegraph is organized as JSON lines, where each line represents a vertex or an edge in a graph.
{"id": "1", "type": "vertex", "label": "metaData", "version": "0.4.3", "projectRoot": "file:///lsif-go", "toolInfo": {"name": "lsif-go"}} {"id": "2", "type": "vertex", "label": "project"} {"id": "3", "type": "vertex", "label": "document", "uri": "file:///lsif-go/internal/gomod/module.go"} {"id": "4", "type": "edge", "label": "contains", "outV": "2", "inVs": ["3"]}
Every vertex and edge in the output must have unique identifier. Edges link two or more vertices together by specifying their identifiers in their outV and inV/inVs properties. An edge may only reference a vertex that has been defined earlier in the file.
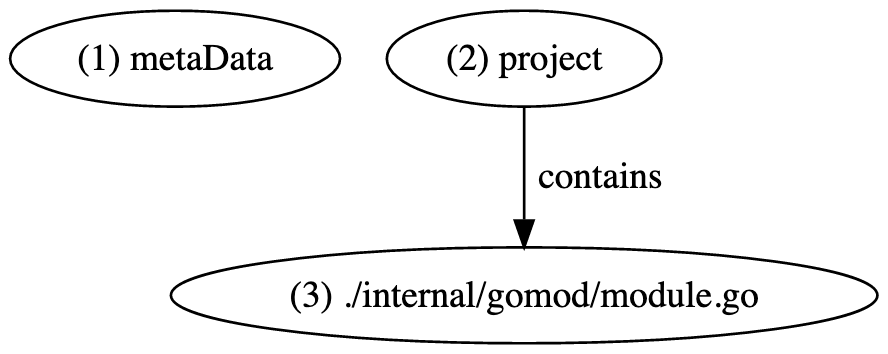
The first line of the file must be a metaData vertex that specifies the LSIF spec version, an absolute URI to the project root, and a toolInfo object that contains the indexer's name.
The next line of the file should be a project vertex. This project contains all of the files being indexed, which are represented as document vertices. Each document vertex specifies an absolute URI to the file on disk. This URI will generally be a proper superstring of the project root specified earlier, but may not be if you are indexing only a subset of a project that relies on files outside your target root. Including these documents is perfectly fine and still results in valid LSIF.
Documents and projects are linked via a contains relationship. This relationship is directed from the parent to its children and can be visualized as follows. Contains is a one-to-many edge relationship -- as a project may contain many documents, the contains edge for a project may specify many destination vertex identifiers.
Ranges
A range vertex specifies a range of character positions in a document that correspond with a symbol in the source code. This symbol may define a class, interface, struct, variable, constant, or package. The occurrence of the symbol may be a definition, or it may be a reference to a definition elsewhere. The range only tells us a location where a symbol is, but does not provide any additional semantic information about it. Additional semantic meaning is attached to ranges via edges to other vertices, as we'll cover later in the document.
Take, for example, the symbol run defined as follows.
func InferModuleVersion(projectRoot string) (string, error) { // Step 1: see if the current commit is tagged. If it is, we return // just the tag without a commit attached to it. tag, err := run(projectRoot, "git", "tag", "-l", "--points-at", "HEAD") // ... }
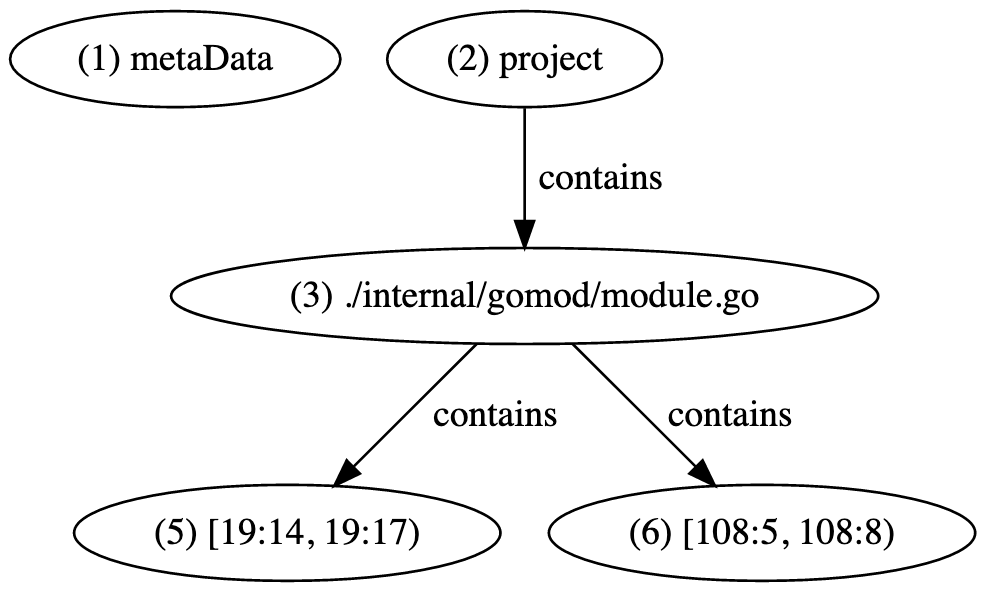
Ranges in LSIF are zero-indexed and specify a half-open interval. This symbol begins on line 19 character 14 and is three characters long. This range is represented in LSIF as vertex 5 in the following fragment. Vertex 6 represents the definition of the same symbol in the same document.
{"id": "5", "type": "vertex", "label": "range", "start": {"line": 19, "character": 14}, "end": {"line": 19, "character": 17}} {"id": "6", "type": "vertex", "label": "range", "start": {"line": 108, "character": 5}, "end": {"line": 108, "character": 8}}
Ranges must belong to exactly one document via the contains relationship, which is specified in the same way we link projects to the documents it contains.
{"id": "7", "type": "edge", "label": "contains", "outV": "3", "inVs": ["5", "6"]}
Our LSIF output can now be visualized as follows.
Result sets
In the next section we will see how semantic meaning is attached to a range via its relationship to definition, reference, and hover vertices, but first we make a small detour. Imagine the definition of a type that is defined once and used in dozens or hundreds of places in the same project. Take the definition of VertexLabel as an example, which is a common type alias for a string in the lsif-go source code. Each reference to this type will point to the same definition, and each reference will also have the same hover text.
A resultSet vertex acts as a surrogate for a set of ranges that have the same relationships to other vertices. Instead of linking the same definition, reference, and hover vertices to many ranges, we can attach them to a single result set and in turn attach the result set to the target ranges. This can substantially reduce the number of edges in the relationship.
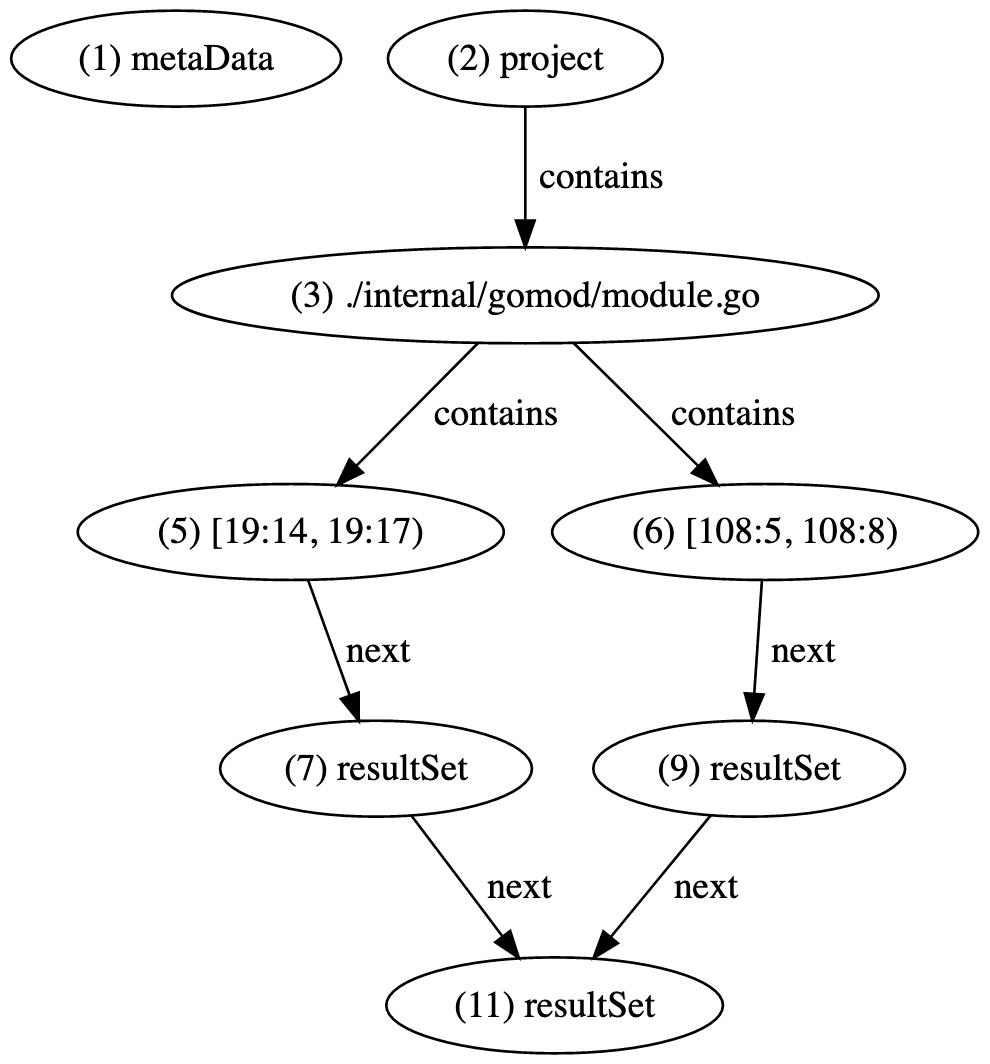
Result sets are defined and attached to range vertices as follows.
{"id": "7", "type": "vertex", "label": "resultSet"} {"id": "8", "type": "edge", "label": "next", "outV": "5", "inV": "7"} {"id": "9", "type": "vertex", "label": "resultSet"} {"id": "10", "type": "edge", "label": "next", "outV": "6", "inV": "9"}
It is also possible to attach result sets to other result sets, forming a chain.
{"id": "11", "type": "vertex", "label": "resultSet"} {"id": "12", "type": "edge", "label": "next", "outV": "7", "inV": "11"} {"id": "13", "type": "edge", "label": "next", "outV": "9", "inV": "11"}
Using result sets, our LSIF output can now be visualized as follows.
Now we can get back to business!
Attaching semantic meaning to ranges
Sourcegraph currently processes only a subset of the LSIF input which includes definitions and reference relationships between ranges (to support jump-to-definition and find-references operations), and the hover text for ranges (to support hover tooltips). We will soon be extending our backend to include support for diagnostics. This section details only what is currently supported by Sourcegraph.
Specifying hover text
Hover text in LSIF is specified as a hoverResult vertex with a result property specifying the hover contents as defined in the LSIF/LSP specification. In this example, the content is a two-element list. The first is the signature of the definition specified as a go string. The second element is a markdown-formatted doc string that occurs in the doc comment above the definition.
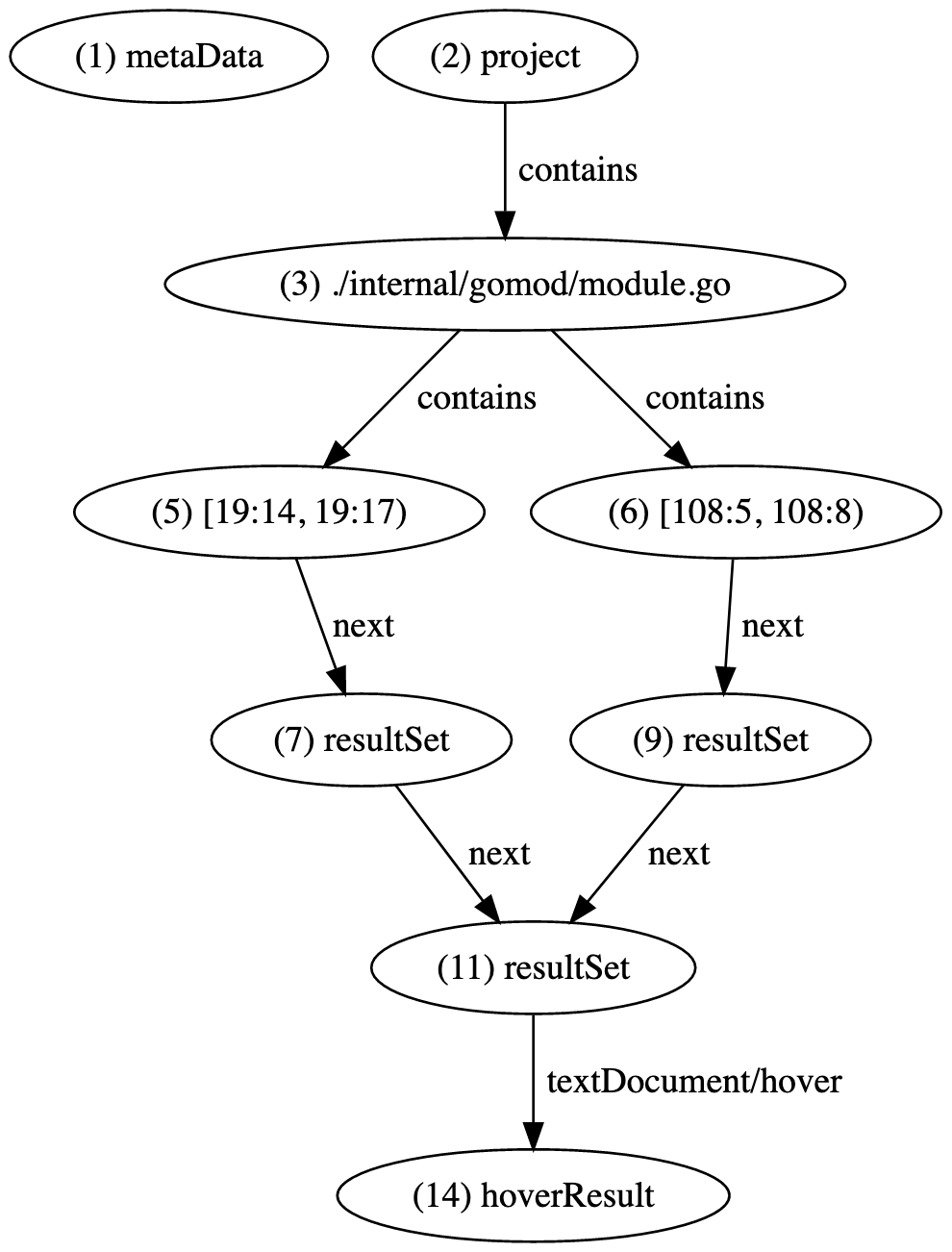
Hover results are attached to ranges or result sets via a textDocument/hover edge as follows.
{"id": "14", "type": "vertex", "label": "hoverResult", "result": {"contents": [{"language": "go", "value": "func run(dir string, command string, args ...string) (string, error)"}, "run executes the command ... \n\n"]}} {"id": "15", "type": "edge", "label": "textDocument/hover", "outV": "11", "inV": "14"}
The contents property of a hover result is composed of a list of segments which are formatted independently then concatenated. If a segment is a bare string, it is rendered as markdown. If it is an object indicating a language and a value, it will be formatted as code and highlighted based on the language identifier.
Using result sets, our LSIF output can now be visualized as follows, and the hover text is now (indirectly) attached to both the definition and reference ranges defined earlier.
Linking definitions and references together
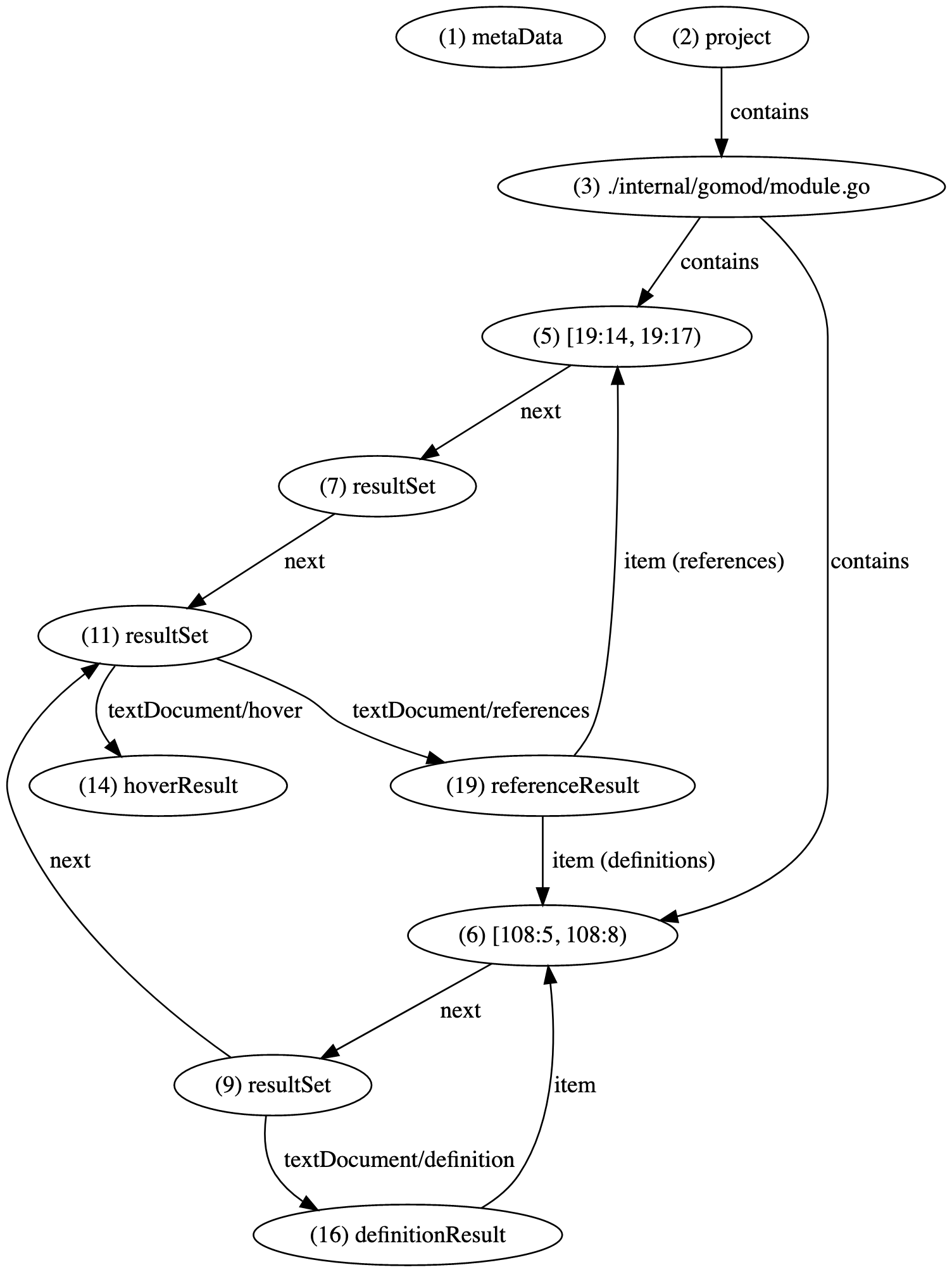
For each range corresponding to a definition we create a definitionResult vertex. This should be attached directly to the range, or to a resultSet that is not shared with another range that does not define that symbol via a textDocument/definition edge. Here, we'll choose to attach it to the definition range's result set, but it would also be valid to attach it directly to the definition range.
{"id": "16", "type": "vertex", "label": "definitionResult"} {"id": "17", "type": "edge", "label": "textDocument/definition", "outV": "9", "inV": "16"}
For each definition that is referenced at least once, we create a referenceResult vertex. This vertex should be reachable from each range that references the target symbol via a textDocument/references edge. Here, we'll choose to attach it to the shared result set, but it would also be valid to have an edge from each range or from the other two result sets.
{"id": "18", "type": "vertex", "label": "referenceResult"} {"id": "19", "type": "edge", "label": "textDocument/references", "outV": "11", "inV": "18"}
Finally, we fill out the relationships in the opposite direction. The definition result needs to link back to the range that defines it via an item edge, and the reference result needs to link back to the set of ranges that define the symbol, and the set of ranges that reference the symbol via item edges tagged with a definitions and references property, respectively.
{"id": "20", "type": "edge", "label": "item", "outV": "16", "inVs": ["6"], "document": "3"} {"id": "21", "type": "edge", "label": "item", "outV": "18", "inVs": ["6"], "document": "3", "property": "definitions"} {"id": "22", "type": "edge", "label": "item", "outV": "18", "inVs": ["5"], "document": "3", "property": "references"}
Each item edge has a document property that specifies the document that contains all of the inVs ranges. In cases where multiple ranges reference the same definition from separate documents, multiple item edges are necessary.
Our LSIF output can now be visualized as follows.
Monikers
The previous section detailed how to link definitions and references together, but that only works when the definition and reference reside in the same project (and in documents that are both indexed at the same time). Monikers allow us to attach names to ranges and result sets in a way that allows us to link names together between distinct indexes. This enables us to perform cross-repository jump-to-definition and global find-reference operations.
Each imported package gets an associated packageInformation vertex, and each use of an imported symbol is linked to a moniker which gets linked to that package. Conversely, the index defines a packageInformation vertex representing exported symbols, and each exported symbol is associated with a unique moniker linked to that packageInformation vertex.
For this section, we will use a new source code fragment as our example, shown below.
import doc "github.com/slimsag/godocmd" func constructMarkedString(s, comments, extra string) ([]protocol.MarkedString, error) { // ... if comments != "" { var b bytes.Buffer doc.ToMarkdown(&b, comments, nil) contents = append(contents, protocol.RawMarkedString(b.String())) } // ... }
The call doc.ToMarkdown(...) refers to a function defined in a remote package. In order to support a remote jump-to-definition operation (assuming that the remote package has also been indexed), we need to give the definition a stable name that will be the same in both indexes, and we need to emit enough information to determine in what remote index the definition lives.
We create a moniker vertex with a kind property specifying the direction of dependency (import for a remote definition and export for a definition that can be used remotely in other indexes), a scheme property that indicates the source of the moniker, and an identifier property. Moniker identifiers should be unique within the specified scheme in a single LSIF index (such that two monikers with the same scheme and identifier should refer to the same symbol), but is not necessarily unique across indexes.
We also create a packageInformation vertex that specifies name, manager, and version properties. The value of the name and value properties should refer to the package dependency (in the case of an import moniker), or should refer to the package being provided by the project/document being indexed (in the case of an export moniker). The value for the manager property should be the name of the package management system (e.g. npm, gomod, pip) providing the package.
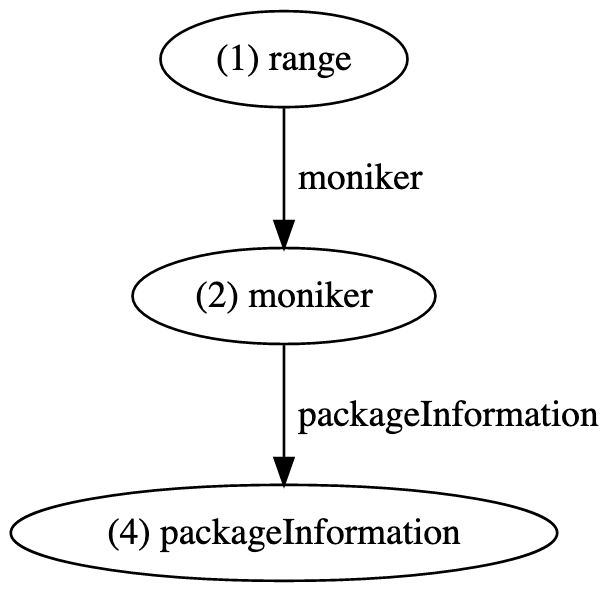
Monikers are attached to ranges or result sets via a moniker edge, and package information vertices are attached to moniker vertices via a packageInformation edge, as follows.
{"id": "1", "type": "vertex", "label": "range", "start": {"line": 78, "character": 6}, "end": {"line": 78, "character": 16}} {"id": "2", "type": "vertex", "label": "moniker", "kind": "import", "scheme": "gomod", "identifier": "github.com/slimsag/godocmd:ToMarkdown"} {"id": "3", "type": "edge", "label": "moniker", "outV": "1", "inV": "2"} {"id": "4", "type": "vertex", "label": "packageInformation", "name": "github.com/slimsag/godocmd", "manager": "gomod", "version": "v0.0.0-a1005ad29fe3"} {"id": "5", "type": "edge", "label": "packageInformation", "outV": "2", "inV": "4"}
This very simple graph fragment can be visualized as follows.
Some tools populate monikers in a multi-pass process. This is how early versions of lsif-go worked, and how lsif-tsc currently works. The first pass will export import and export monikers but no package information. The second pass outputs additional monikers that are correlated with the package information (using the contents of a dependency manifest such as a go.mod file or a package.json).
As an illustrative example, we suppose that the first pass of lsif-go outputs monikers with the go scheme but no package information.
{"id": "1", "type": "vertex", "label": "range", "start": {"line": 78, "character": 6}, "end": {"line": 78, "character": 16}} {"id": "2", "type": "vertex", "label": "moniker", "kind": "import", "scheme": "go", "identifier": "github.com/slimsag/godocmd:ToMarkdown"} {"id": "3", "type": "edge", "label": "moniker", "outV": "1", "inV": "2"}
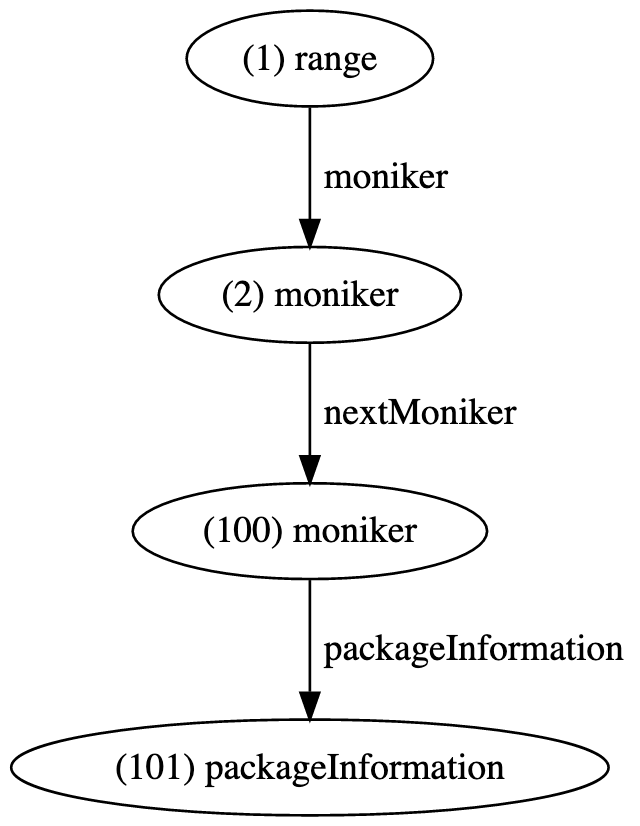
The second pass then reads each moniker from the first pass, correlates the package from the moniker identifier, and outputs a second moniker correlated with package information. Monikers can be attached to other monikers via a nextMoniker edge. This forms a chain of monikers, each of which are attached (indirectly) to a range or set of ranges.
{"id": "100", "type": "vertex", "label": "moniker", "kind": "import", "scheme": "gomod", "identifier": "github.com/slimsag/godocmd:ToMarkdown"} {"id": "101", "type": "vertex", "label": "packageInformation", "name": "github.com/slimsag/godocmd", "manager": "gomod", "version": "v0.0.0-a1005ad29fe3"} {"id": "102", "type": "edge", "label": "nextMoniker", "outV": "2", "inV": "100"} {"id": "103", "type": "edge", "label": "packageInformation", "outV": "100", "inV": "101"}